FREE: Managing fraud with visual link analysis
The ultimate guide to the role of link analysis and timeline visualization in fraud detection, investigation and prevention.
Enterprise fraud detection has changed significantly in the last few years. Previously, single supplier solutions reigned supreme. Multi-million dollar contracts were signed for end-to-end fraud management platforms that managed the process from data ingestion through to case investigation.
Increasingly, this ‘one size fits all’ approach is falling out of favor. Strong innovation in data storage, processing and visualization has led organizations towards a modular approach to enterprise fraud management. Many now prefer to build their own tools, customized for their own specific users, pain points and scenarios.
These tools run rule-based, risk-scoring algorithms against billions of data points to transform unstructured data into useful intelligence. They use machine learning to create profiles of normal behavior and flag anomalies and outliers. To help users drill down further into flagged cases, organizations integrate powerful link analysis technologies into their systems.
In this post, we’ll see how these modular fraud detection systems fit together.
In many domains, fraud detection can be a surprisingly ad-hoc task. Fraud may only be investigated if it’s been spotted by a colleague or customer after the fact. When you think of the volume of data financial institutions have from digital and non-digital channels, this approach isn’t scalable.
Legacy IT systems also make data inaccessible. In one large bank we visited, customer data was spread across nearly 100 different systems. It’s no surprise that the industry needs new technologies to provide more proactive and automated fraud detection.
Link analysis (also known as graph visualization or network visualization) helps detect a huge range of fraud, including:
Customer (external) fraud
Internal (employee) fraud:
It’s not just for banks, either. Similar processes can be used by insurers, gambling companies, foreign exchanges, credit firms, tax agencies, etc. Link analysis also helps with anti-money laundering (AML) and Know Your Customer (KYC) tasks.

The ultimate guide to the role of link analysis and timeline visualization in fraud detection, investigation and prevention.
We’ve found six distinct steps to enterprise fraud detection architectures:
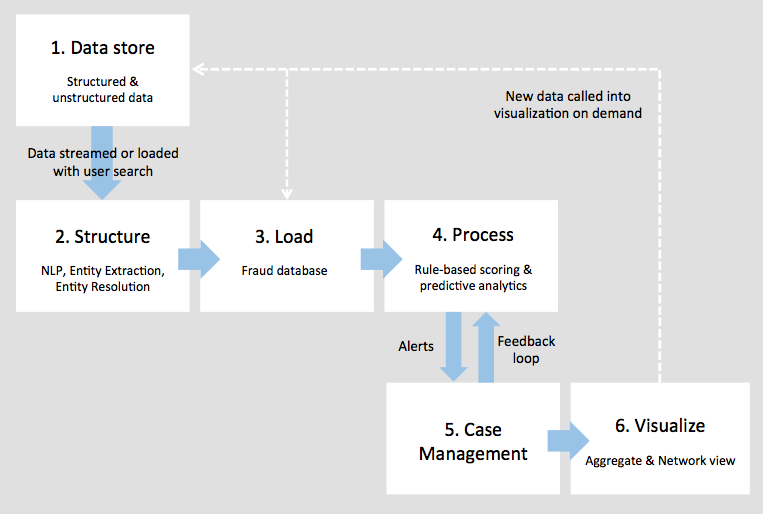
The process begins with the raw data records. These may be held in multiple formats and locations around the business, and include many different record types, including:
Structured data:New data is streamed in real-time into the workflow or loaded in batch processes.
The next step is to structure our growing mountain of data, so it’s easier to index and search.
Many organizations use Natural Language Processing (NLP), which uses algorithms and machine learning tools to interpret data. That could mean scanning through the content of an email, or through voice traffic to interpret phone conversations.
An essential part of NLP is entity extraction. This finds and tags specific objects we want to define in our data model and the relationships that exist between them. They could be names, email addresses, bank accounts, or anything else important. We define the network structure to explore later using link analysis.
Once tagged, entity resolution collates duplicate objects into single entities. This may be ‘exact’, e.g. aggregating all the accounts with a specific account number, or ‘fuzzy’, e.g. aggregating references to ‘Mr Jonathan Smith’ (J. Smith, John Smith, etc).
These three processes combined create a single ‘master’ view of our data and its connections.
Next we need a storage solution that’ll let us run queries against our data easily and get results quickly. Existing databases are unlikely to be responsive enough, so many organizations will federate data in an additional database.
Graph databases have been optimized to store connected data as a network of entities (nodes) and relationships (edges). They’re popular options for fraud databases. Other NoSQL or Relational Databases are also used. For more on these database options, see:Now we’ve chosen our storage solution, we can stream or batch-load our structured data into the fraud database.
Next up is to process our data so we know which events require further investigation. By this point, you may have tens of billions of nodes and edges in your database. Even with KeyLines’ new WebGL renderer, you won’t be able to visually explore them all simultaneously.
Instead, we can use a rule-based scoring system to create a relative risk indicator. This flags events (e.g. mortgage applications, bank transfers, credit card transactions, etc.) that follow known fraudulent behavior patterns. These risk models and business rules are usually manually created and maintained. The highest scoring incidents will move to the next stage of our workflow.
A more modern approach to risk scoring makes use of machine learning algorithms and predictive analytics to refine the complex risk models in real-time. Behavioral analytics create profiles of historic ‘normal’ user behavior and flags unusual activity, adds user-by-user oversight too.
Feedback loops are a good way to hone the process further. Information about false negatives (i.e. activity that was flagged as suspicious but later turned out innocent) is used to inform and develop the existing process.
Once an event is flagged as high-risk, it’s pushed to the next stage of our process.
The output of stages 1 to 4 is an alert, which is manually investigated using a case management tool.
Investigators often work to strict deadlines. They must make decisions in seconds but still follow established best practices. For this reason, case management tools tend to enforce a strict user workflow, and create a ‘single window’ experience, so investigators don’t need to change tools for different tasks.
They typically contain data dashboards to show aggregated and network views of data, which leads us to the final stage of the workflow.
Now our data has been structured, loaded, processed and prioritized, we can use visualization tools to understand it.
Link analysis technologies, like KeyLines, provide investigators with a user-friendly, consolidated view of the data they need to investigate. By interacting with different nodes and links, they can make sense of complicated situations and make informed decisions quickly. Combined with a geospatial and temporal view of the data, they can also begin to understand events in terms of geography and time.
Our previous blog post explains how link analysis techniques help with fraud detection in more detail.
This modular approach to fraud detection means organizations can choose the right best-in-breed tool for each job.
The slow pace of innovation in many end-to-end platforms doesn’t have to slow you down. Instead, use a composite solution to make fraud detection an efficient, more automated procedure that’s custom-built to address your business needs. The KeyLines link analysis toolkit is compatible with virtually any technology stack and can be easily incorporated into this workflow.
Try KeyLines for yourself to start your graph visualization journey.
Visualize your data! Request full access to our SDKs, demos and live-coding playgrounds.
Registered in England and Wales with Company Number 07625370 | VAT Number 113 1740 61
6-8 Hills Road, Cambridge, CB2 1JP. All material © Cambridge Intelligence .
Privacy Policy | Security Framework



