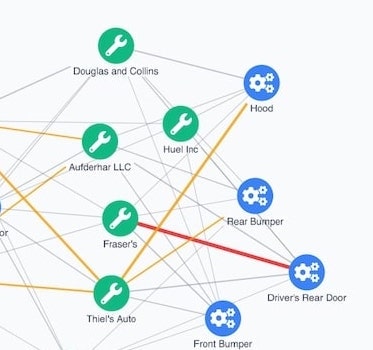
Visualizing ArangoDB
Build powerful graph & timeline tools on ArangoDB
Ship ArangoDB graph apps quickly and easily
Our developer toolkits make building graph and timeline visualization apps with ArangoDB a breeze.
Combining performance with a hassle-free developer experience, they provide a completely flexible way to create graph and timeline visualization UIs that work anywhere, on any device.
They also integrate seamlessly with ArangoDB, giving your users an intuitive and interactive way to visualize and explore the data they need to understand.
About our toolkits
Our toolkits – KeyLines, ReGraph and KronoGraph – are software development kits (SDKs) for graph and timeline visualization.
They make it easy to create powerful interactive visualization tools that bring your data to life. These tools can then be rolled into your existing workflows and products, helping your users to explore and understand their data.
Our SDKs are 100% database agnostic, but integrate seamlessly with ArangoDB. They also work with any browser, device or server, leaving you free to choose the stack that works best for you.
Building timeline and graph visualization tools for ArangoDB
Whatever your stack, we have an integration tutorial to get you started.
Learn how to create graph and timeline visualization applications that empower users to see, explore and understand the data in their ArangoDB database.
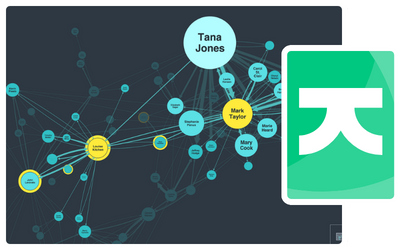
KeyLines: Graph visualization for JavaScript developers
Enjoy the flexibility to code how you like. Add graph visualization to your applications that work anywhere, as part of any stack.
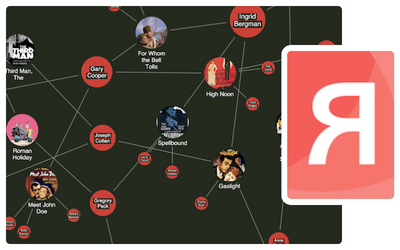
ReGraph: Graph visualization for React developers
With ReGraph’s simple data-driven API, it’s quick and easy to add graph visualizations to your React applications.
Why do ArangoDB users choose our toolkits?

The fastest route
We design our toolkits with a fast developer experience in mind.
Equipped with our demos, coding playgrounds, comprehensive docs and expert support, you’ll be ready to ship your application in no time.
An easy integration
Thanks to the Foxx microservice framework, integration with ArangoDB is simple and fast. Take advantage of our tutorials, demos, documentation and support to get started quickly.

Deliver the best UX
Our toolkits let you customize every aspect of your ArangoDB application – from branding to functionality.
The result is useful, insightful experiences your users value, and your competitors envy.
Powerful functionality
From timelines to centrality measures, automated layouts to geospatial maps.
Our SDKs have a huge range of visualization functions and analysis algorithms to uncover insight in your most complex ArangoDB datasets.

A trusted partner
We’ve been the leading provider of graph and timeline visualization technologies since 2011.
Hundreds of organizations worldwide rely on our toolkits – from pioneering startups to Fortune 500s and national governments.
Harness our innovation
We work year-round creating new features, ready to roll into your apps.
Keep customers happy and competitors on the back foot with constantly-improving, beautiful and unique visual analytics.
Ready to build your ArangoDB data visualization app?
Who uses our toolkits?
Follow in the footsteps of over 300 organizations already using our toolkits to build and deploy powerful graph and timeline visualization applications.






ArangoDB Visualization FAQ
ArangoDB is a native multi-model open-source database optimized for connected data. It combines the strengths of three major NoSQL data models: graph, document and key-value stores.
Its triple model / single query approach helps developers build datastores with outstanding flexibility and power, without the risk and complexity of multiple stacks.
ArangoDB offers the ArangoDB WebUI – a configurable visualization tool designed for database developers who need to create and manage data structures and schemas.
If you need a fast way to build custom and powerful graph applications, and ship them to your end-users, you need a dedicated connected data visualization technology like KeyLines, ReGraph or KronoGraph.
KeyLines is our JavaScript software development toolkit (SDK) for graph visualization. It makes it quick and easy for JavaScript developers to build custom, powerful and interactive graph visualization tools. These can be rolled into your existing products and shipped to unlimited end-users.
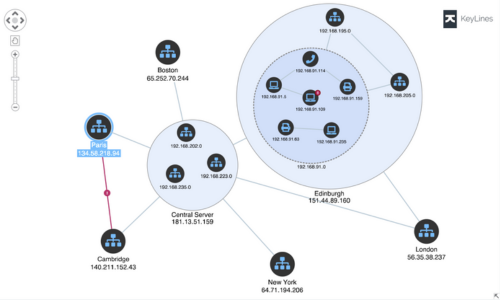
ReGraph is our React SDK for graph visualization. It offers the same performance, scalability and end-user functionality as KeyLines, but is specifically designed for React developers.
Every aspect of the SDK is optimized to feel as ‘React-native’ for the developer as possible, including fully-reactive components, state and data flow management and JSX-coded elements with clear syntax.
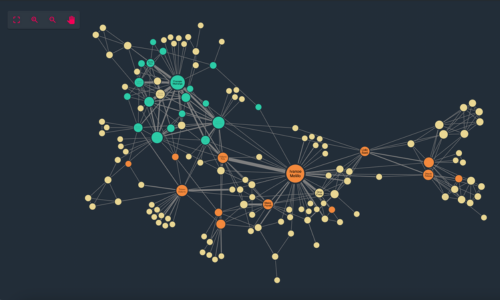
KronoGraph is our SDK for building interactive timeline applications. It comes with both plain JavaScript and React APIs.
The timelines built with KronoGraph reveal how events unfold over time, including heatmap views, individual event views, and intelligence data aggregation.
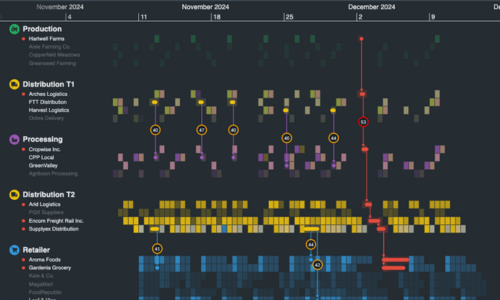
The toolkits are front-end JavaScript components, so you choose how to connect them to ArangoDB. Most people opt to harness the Foxx microservice framework.
Our tutorial shows a couple of examples, but the overall approach is:
- The end-user accesses a visualization chart in their web browser, built with one of our visualization SDKs
- Each event performed in the chart, e.g. a click, right-click, hover, etc., raises a query to the ArangoDB database
- Some custom code raises this query as a jQuery AJAX request, which is natively translated into a Arango Query Language (AQL)
- ArangoDB returns the required data as a JSON object
- The visualization chart renders the JSON data in the browser.
Hundreds of organizations worldwide use our toolkits to make sense of complex connected data. Their industry sectors include: security and intelligence, law enforcement, fraud detection, infrastructure management and cyber threat intelligence.
If you’re not ready to get started yet, take a look at our blog. You’ll find useful information on all aspects of graph database visualization and best practice.
If you want to explore your options with other graph databases, please visit our visualizing graph databases page.
You might also find this webinar, showing how ArangoDB and KeyLines work together, useful.